CrossLoc: Scalable Aerial Localization Assisted by Multimodal Synthetic Data
CVPR 2022
Qi Yan, Jianhao Zheng, Simon Reding, Shanci Li, Iordan Doytchinov
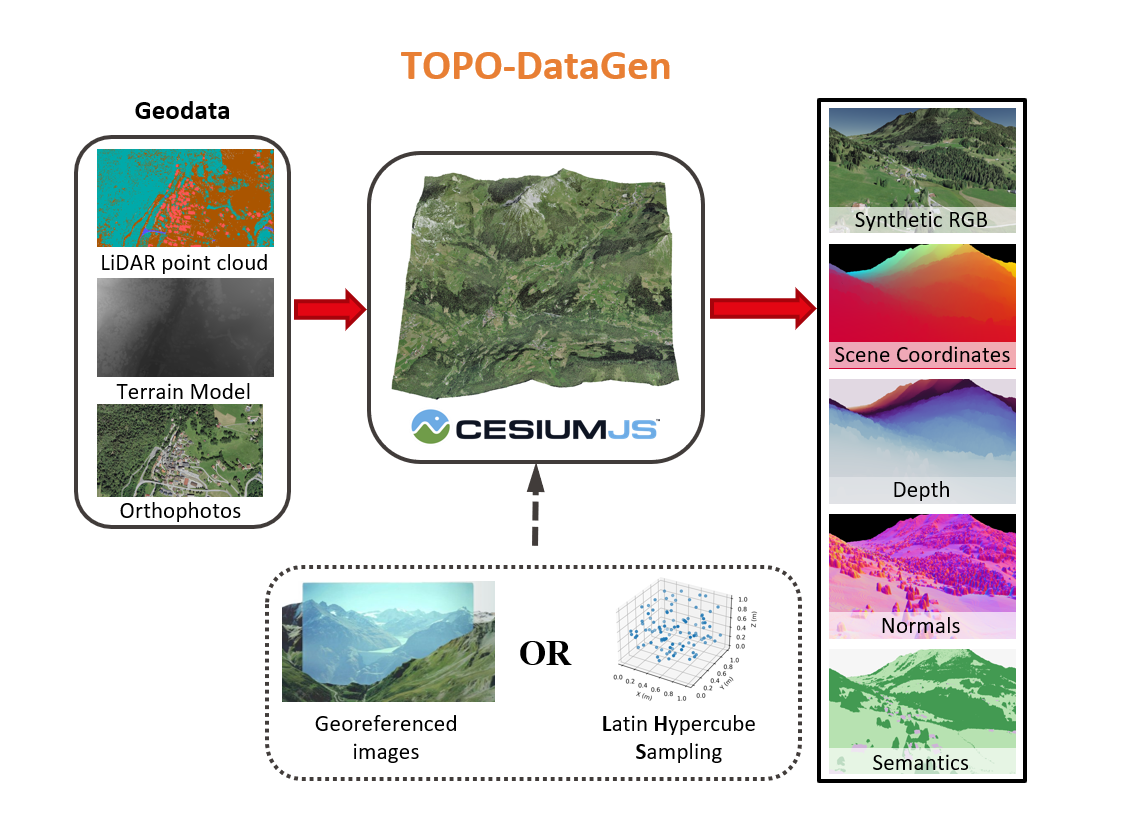
TOPO-DataGen is generically useful for enhancing aerial visual localization networks.
The proposed data generation workflow outputs both 2D RGB images and the associated 3D labels such as the pixel-wise
scene coordinates.
It has the following advantages:
Obtaining dense and accurate 2D-3D correspondences without much engineering efforts, unlike the structure-from-motion.
Seamless traversing between the real and virtual world hinged on the camera viewpoint.
Work for both image-based methods such as absolute pose regression and structure-based methods that require 3D labels.





CrossLoc: Scalable Aerial Localization Assisted by Multimodal Synthetic Data
CVPR 2022
CVPR Camera Ready
@article{yan2021crossloc,
title={CrossLoc: Scalable Aerial Localization Assisted by Multimodal Synthetic Data},
author={Yan, Qi and Zheng, Jianhao and Reding, Simon and Li, Shanci and Doytchinov, Iordan},
journal={arXiv preprint arXiv:2112.09081},
year={2021}
}@misc{iordan2022crossloc,
title={CrossLoc Benchmark Datasets},
author={Doytchinov, Iordan and Yan, Qi and Zheng, Jianhao and Reding, Simon and Li, Shanci},
publisher={Dryad},
doi={10.5061/DRYAD.MGQNK991C},
url={http://datadryad.org/stash/dataset/doi:10.5061/dryad.mgqnk991c},
year={2022}
}




